이전 내용은 아래 글에서 확인 부탁 드리겠습니다.
[Data Analysis/기타 데이터] - [기타 데이터] Wine 데이터 분석 (데이터 확인 / 질문하기 / 데이터 전처리)
[기타 데이터] Wine 데이터 분석 (데이터 확인 / 질문하기 / 데이터 전처리)
Wine 데이터 분석 포르투갈 비노 베르데(Vinho Verde) 지역의 레드와 화이트 와인의 데이터가 들어있는 데이터 셋. 데이터 출처 : https://archive.ics.uci.edu/ml/datasets/wine+quality UCI Mach..
sks8410.tistory.com
4. EDA & Visualization
4-1 각 와인 퀄리티 당 몇개의 와인이 있을까?
# 전체 와인의 퀄리티 당 와인 수
wine["quality"].value_counts()
# 전체 와인의 퀄리티 당 와인 수 시각화
wine_quality = wine["quality"].value_counts()
fig = px.bar(wine_quality, x = wine_quality.index, y = "quality",
text = "quality")
fig.update_traces(
textposition = "outside",
textfont_color = "black"
)
fig.update_layout(
title = dict(
text = "<b>전체 와인 퀄리티 당 와인 수</b>",
font_size = 20
),
xaxis = dict(
title = "와인 퀄리티"
),
yaxis = dict(
title = "와인 수"
),
template = "plotly_white"
)
fig.show()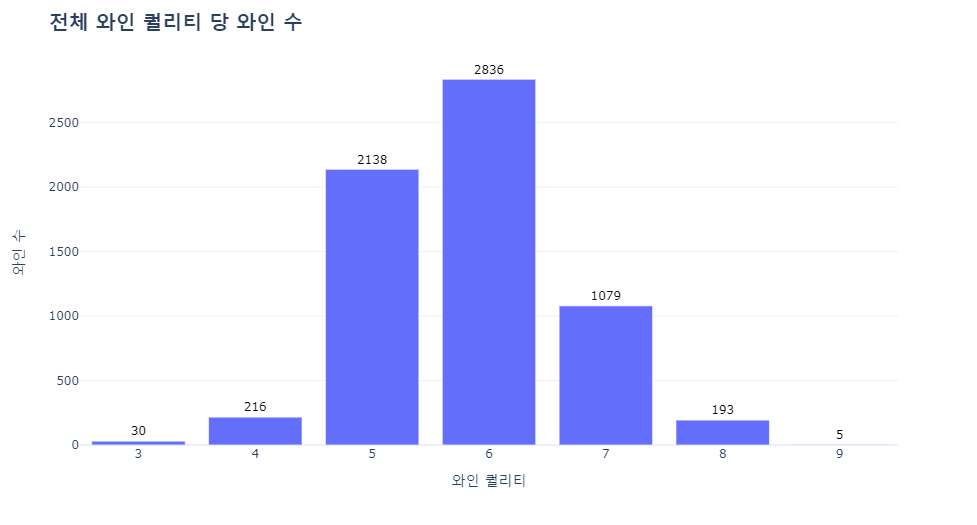
와인 등급이 6등급인 와인이 가장 많고 5등급 > 7등급 순으로 많이 있습니다.
# red / white 별로 나눠서 퀄리티별 와인 수 확인
wine_tag_quality = wine.groupby("tag")["quality"].value_counts().unstack(0)
wine_tag_quality
# red / white 별로 나눈 퀄리티별 와인 수 시각화
wine_tag_quality = wine_tag_quality.reset_index()
fig = go.Figure()
fig.add_trace(
go.Bar(x = wine_tag_quality["quality"], y = wine_tag_quality["r"],
name = "Red", text = wine_tag_quality["r"])
)
fig.add_trace(
go.Bar(x = wine_tag_quality["quality"], y = wine_tag_quality["w"],
name = "White", text = wine_tag_quality["w"])
)
fig.update_traces(
textposition = "outside",
textfont_color = "black"
)
fig.update_layout(
title = dict(
text = "<b>와인별 퀄리티 당 와인 수</b>",
font_size = 20
),
xaxis = dict(
title = "와인 퀄리티"
),
yaxis = dict(
title = "와인 수"
),
template = "plotly_white"
)
fig.show()
레드와인은 5등급이 가장 많고, 화이트와인은 6등급이 가장 많이 있습니다.
4-2 각 컬럼 데이터의 분포 확인
# 각 컬럼 데이터의 분포 시각화
for i in wine.columns :
if i == "quality":
break
fig = px.box(wine, x = "quality", y = i, color = "quality")
fig.update_layout(
title = dict(
text = i + " 컬럼",
font_size = 20
),
template = "plotly_white"
)
fig.show()



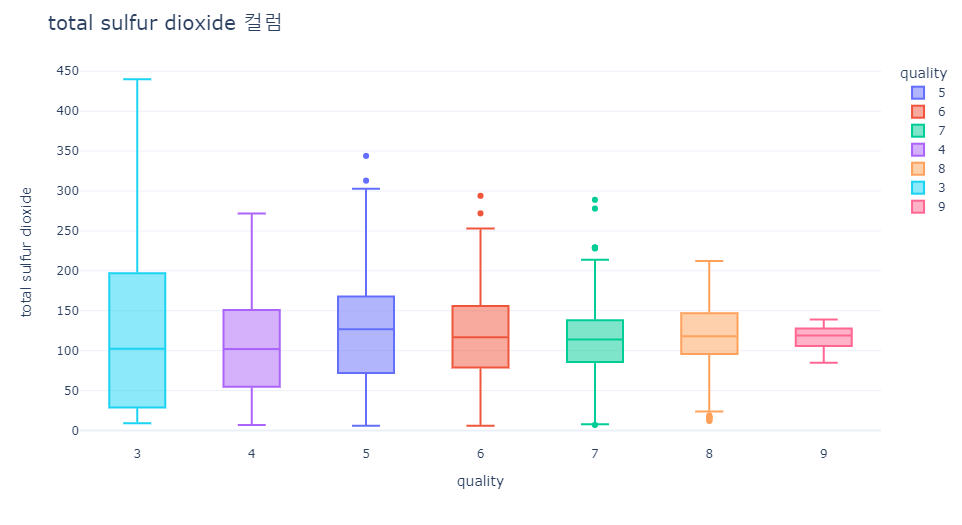




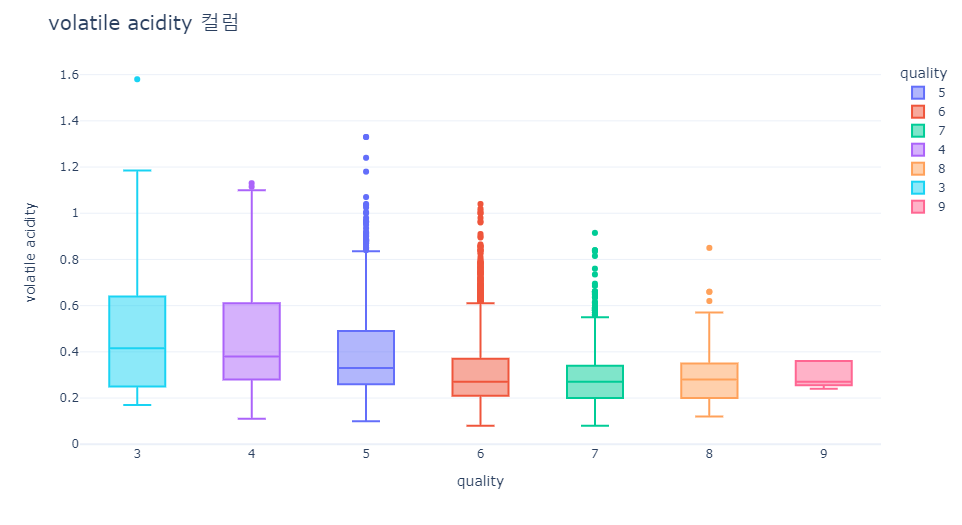

- citric acid, alcohol은 퀄리티가 높아질수록 값이 올라가는 경향을 보이고 있습니다.
- volatile acidity, chlorides은 퀄리티가 높아질수록 값이 내려가는 경향을 보이고 있습니다.
4-3 와인의 어떤 특성이 와인 퀄리티와 가장 밀접한 관련이 있을까?
# 컬럼의 상관관계 히트맵으로 확인
wine_corr = wine.corr().round(2)
import plotly.figure_factory as ff
fig = ff.create_annotated_heatmap(x = wine_corr.index.tolist(),
y = wine_corr.columns.tolist(),
z = wine_corr.values,
xgap = 1,
ygap = 1,
showscale = True)
fig.update_layout(
title = dict(
text = "<b>컬럼간 상관관계 Heat Map</b>",
y = 0.9,
font_size = 20
),
xaxis = dict(
side = "bottom" # x 축 위치 조정
),
yaxis_autorange='reversed'
)
fig.show()
quality는 alcohol 과 강한 양(+)의 상관관계를 가지고 있으며, density, volatile acidity 와 강한 음(-)의 상관관계를 가지고있습니다.
5. Review
1) 각 퀄리티 당 몇개의 와인이 있을까?
> 6등급이 가장 많고 5등급 -> 7등급 순으로 많다는 것을 알 수 있습니다.
> 레드와인은 5등급이 가장 많고, 화이트와인은 6등급이 가장 많다는 것을 알 수 있습니다.
2) 각 컬럼 데이터 분포 확인
> citric acid, alcohol은 퀄리티가 높아질수록 값이 올라가는 경향을 보이고 있습니다.
> volatile acidity, chlorides은 퀄리티가 높아질수록 값이 내려가는 경향을 보이고 있습니다.
3) 와인의 어떤 특성이 와인 퀄리티와 가장 밀접한 관련이 있을까?
> quality는 alcohol 과 강한 양의 상관관계를 가지고 있으며, density, volatile acidity 와 강한 음의 상관
관계를 가지고 있습니다.
'Data Analysis > 기타 데이터' 카테고리의 다른 글
| [기타 데이터] Wine 데이터 분석 1 (데이터 확인 / 질문하기 / 데이터 전처리) (0) | 2021.10.22 |
|---|---|
| [기타 데이터] Airbnb NewYork 데이터 분석 3 (EDA / 시각화 / 리뷰) (0) | 2021.10.21 |
| [기타 데이터] Airbnb NewYork 데이터 분석 2 (데이터 전처리) (0) | 2021.10.20 |
| [기타 데이터] Airbnb NewYork 데이터 분석 1 (데이터 확인 / 질문) (0) | 2021.10.20 |
| [기타 데이터] Commerce 데이터 분석 3 (EDA / 시각화 / 리뷰) (0) | 2021.10.13 |



