728x90
이 전 내용은 아래 글에서 확인 하실 수 있습니다.
[Data Analysis/기타 데이터] - [기타 데이터] Airbnb NewYork 데이터 분석 1 (데이터 확인 / 질문)
[기타 데이터] Airbnb NewYork 데이터 분석 1 (데이터 확인 / 질문)
Airbnb NewYork 데이터 분석 분석 목적 : 2021년 9월 1일자 에어비앤비 뉴욕 데이터 데이터 출처 : http://insideairbnb.com/get-the-data.html Inside Airbnb. Adding data to the debate. Inside Airbnb is a..
sks8410.tistory.com
3. 데이터 전처리
3-1 중복된 컬럼 확인
bnb.duplicated().sum()
중복된 컬럼은 없습니다.
3-2. 결측치 처리
# name과 host name이 NaN 값인 데이터는 noname 으로 처리
bnb["name"] = bnb["name"].fillna("Noname")
bnb["host_name"] = bnb["host_name"].fillna("Noname")
#bnb[bnb["name"] == "Noname"].head()
bnb[bnb["host_name"] == "Noname"].head()
# id, last_review 컬럼은 사용하지 않을 예정이므로 컬럼 삭제
bnb = bnb.drop(["id", "last_review"], axis = 1)
print(bnb.shape)
bnb.head()
# reviews_per_month 가 NaN 값인 데이터는 리뷰가 없는 것으로 판단하고 0으로 처리
bnb["reviews_per_month"] = bnb["reviews_per_month"].fillna(0)
bnb["reviews_per_month"].isnull().sum()
3-3 이상치(Outlier) 처리
3-3-1 Price 컬럼
# price 컬럼 분포 시각화
f, ax = plt.subplots(1, 1, figsize = (18, 8))
sns.distplot(bnb["price"], hist = True, ax = ax)
ax.set_xlim(-500, 6000) # 범위 조정
ax.set_title("price 컬럼 분포", size = 20)
plt.show()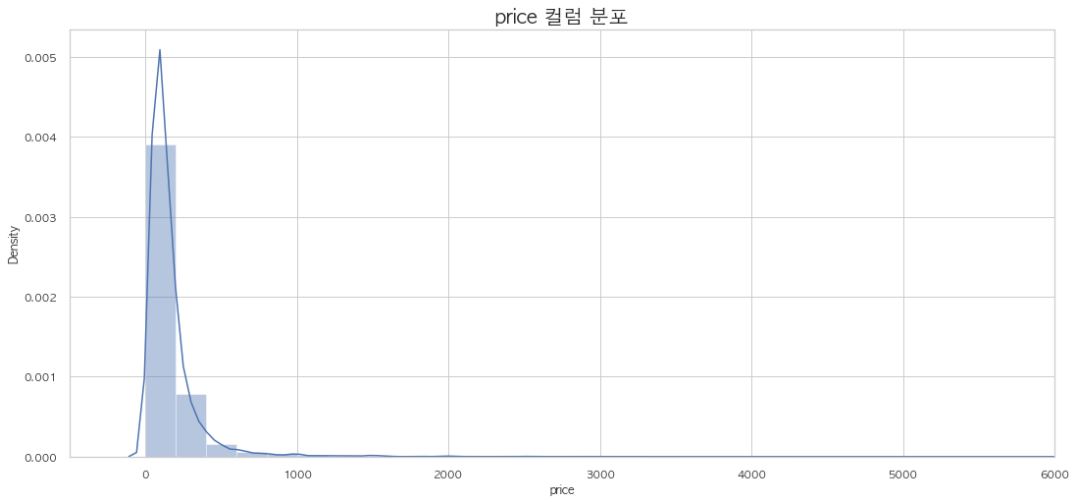
금액대 분포가 1000 이하에 몰려 있습니다.
# skewness, kurtosis 확인
print("skewness: %.2f" %bnb["price"].skew())
print("kurtosis: %.2f" %bnb["price"].kurt())
skewness 와 kurtosis 가 둘 다 매우 높게 나타나므로 이상치가 많이 있다고 볼 수 있습니다.
# threshold 를 정해서 이상치 제거
min_threshold, max_threshold = bnb["price"].quantile([0.01, 0.99]) # 1%와 99% 사이에 있는 값 확인
min_threshold, max_threshold
# threshold min, max 값 범위 밖에 있는 데이터 수 확인
print("30보다 작은 데이터 수:",bnb[bnb["price"] < min_threshold].shape[0])
print("1000보다 큰 데이터 수" ,bnb[bnb["price"] > max_threshold].shape[0])
# min_threshold 와 max_threshold 사이에 있는 데이터만 사용
bnb_thr = bnb[(bnb["price"] > min_threshold) & (bnb["price"] < max_threshold)]
print(bnb_thr.shape)
bnb_thr.head()
# threshold 된 price 컬럼 분포 시각화
f, ax = plt.subplots(1, 1, figsize = (18, 8))
sns.distplot(bnb_thr["price"], hist = True, ax = ax)
ax.set_title("price 컬럼 분포(after threshold)", size = 20)
plt.show()
# thrshold 후 skewness, kurtosis 확인
print("skewness: %.2f" %bnb_thr["price"].skew())
print("kurtosis: %.2f" %bnb_thr["price"].kurt())
skewness 는 정상치 안으로 들어오고, kurtosis 도 많이 줄었습니다.
3-3-2 minimum_nights 컬럼
# minimum_nights 컬럼 분포 시각화
f, ax = plt.subplots(1, 1, figsize = (18, 8))
sns.distplot(bnb_thr["minimum_nights"], hist = True, ax = ax)
ax.set_xlim(-50, 400) # 범위 조정
ax.set_title("minimum_nights 컬럼 분포", size = 20)
plt.show()
대부분이 50일 안쪽으로 분포 되어 있습니다.
# skewness, kurtosis 확인
print("skewness: %.2f" %bnb_thr["minimum_nights"].skew())
print("kurtosis: %.2f" %bnb_thr["minimum_nights"].kurt())
skewness 와 kurtosis 둘 다 매우 높게 나타나므로 이상치가 많이 있는것으로 판단됩니다.
# threshold 를 정해서 이상치 제거
min_threshold, max_threshold = bnb_thr["minimum_nights"].quantile([0.01, 0.99]) # 1%와 99% 사이에 있는 값 확인
min_threshold, max_threshold
# threshold min, max 값 범위 밖에 있는 데이터 수 확인
print("1보다 작은 데이터 수:",bnb_thr[bnb_thr["minimum_nights"] < min_threshold].shape[0])
print("100보다 큰 데이터 수" ,bnb_thr[bnb_thr["minimum_nights"] > max_threshold].shape[0])
# min_threshold 와 max_threshold 사이에 있는 데이터만 사용
bnb_thr = bnb_thr[(bnb_thr["minimum_nights"] > min_threshold) & (bnb_thr["minimum_nights"] < max_threshold)]
print(bnb_thr.shape)
bnb_thr.head()
# threshold 된 minimum_nights 컬럼 분포 시각화
f, ax = plt.subplots(1, 1, figsize = (18, 8))
sns.distplot(bnb_thr["minimum_nights"], hist = True, ax = ax)
ax.set_title("minimum_nights 컬럼 분포(after threshold)", size = 20)
plt.show()
# skewness, kurtosis 확인
print("skewness: %.2f" %bnb_thr["minimum_nights"].skew())
print("kurtosis: %.2f" %bnb_thr["minimum_nights"].kurt())
skewness 는 정상치 안으로 들어왔고, kurtosis 도 많이 줄어든 것을 알 수 있습니다.
728x90
'Data Analysis > 기타 데이터' 카테고리의 다른 글
| [기타 데이터] Wine 데이터 분석 1 (데이터 확인 / 질문하기 / 데이터 전처리) (0) | 2021.10.22 |
|---|---|
| [기타 데이터] Airbnb NewYork 데이터 분석 3 (EDA / 시각화 / 리뷰) (0) | 2021.10.21 |
| [기타 데이터] Airbnb NewYork 데이터 분석 1 (데이터 확인 / 질문) (0) | 2021.10.20 |
| [기타 데이터] Commerce 데이터 분석 3 (EDA / 시각화 / 리뷰) (0) | 2021.10.13 |
| [기타 데이터] Commerce 데이터 분석 2 (데이터 전처리) (0) | 2021.10.12 |



