이전 내용은 아래 글에서 확인 하실 수 있습니다.
[Data Analysis/Kaggle] - [Kaggle] Personal Loan 데이터 분석 1 (데이터 확인 / 질문하기)
[Kaggle] Personal Loan 데이터 분석 1 (데이터 확인 / 질문하기)
Personal Loan 데이터 분석 Personal Loan 데이터는 고객을 더 늘리고자 하는 가상의 은행 데이터입니다. 이 회사의 경영진은 부채를 가진 고객을 개인 대출 고객으로 전환하는 방법을 모색하려고 합
sks8410.tistory.com
[Data Analysis/Kaggle] - [Kaggle] Personal Loan 데이터 분석 2 (데이터 전처리)
[Kaggle] Personal Loan 데이터 분석 2 (데이터 전처리)
이전 내용은 아래 글에서 확인 하실 수 있습니다. [Data Analysis/Kaggle] - [Kaggle] Personal Loan 데이터 분석 1 (데이터 확인 / 질문하기) [Kaggle] Personal Loan 데이터 분석 1 (데이터 확인 / 질문하기) Pe..
sks8410.tistory.com
4. EDA & Visualization
4-1 수입과 대출 사이의 관계 확인
bank_1_loan_income = bank_1.groupby("personal loan")["income"].agg(["mean", "count"])
bank_1_loan_income = bank_1_loan_income.rename(columns = {"mean" : "income mean", "count" : "number of people"})
bank_1_loan_income
대출을 받는 사람의 수입이 대출을 받지 않는 사람보다 약 2배 이상 높다는 것을 알 수 있다.
4-2 월 평균 신용카드 사용액과 대출 사이 관계 확인
bank_1_loan_ccavg = bank_1.groupby("personal loan")["ccavg"].agg(["mean", "count"])
bank_1_loan_ccavg = bank_1_loan_ccavg.rename(columns = {"mean" : "ccavg mean", "count" : "number of people"})
bank_1_loan_ccavg
4-3 가족 인원수와 대출 사이 관계 확인
bank_1_family_loan = bank_1.groupby("family")["personal loan"].agg(["mean", "count"])
bank_1_family_loan = bank_1_family_loan.rename(columns = {"mean" : "personal loan mean", "count" : "number of people"})
bank_1_family_loan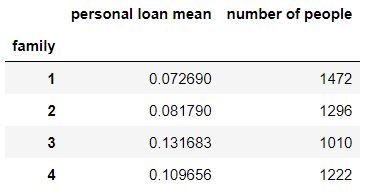
# 가족 인원수와 대출 사이 관계 시각화
layout = {
"title" : {
"text" : "<b>가족 인원수와 대출 사이 관계</b>",
},
"xaxis" : {
"showticklabels" : True,
"dtick" : 1,
"title" : "가족 인원수"},
"yaxis" : {
"title" : "대출"}
}
bank_1_family_loan["personal loan mean"].iplot(kind = "bar", layout = layout)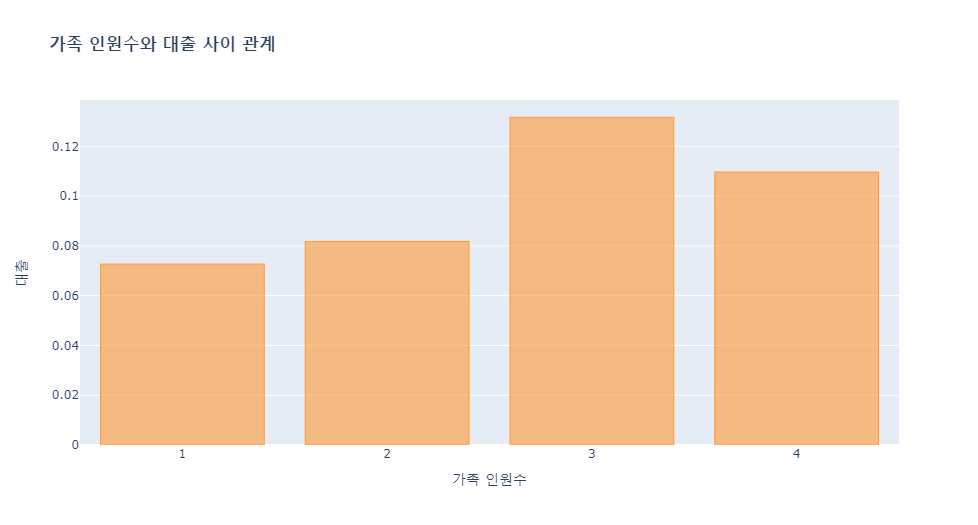
가족 인원이 3명일때 가장 대출을 많이 받은 것을 알 수 있습니다.
가족 인원이 증가할 수록 대출을 많이 받는 경향이 있지만 정비례하지는 않다는 것을 알 수 있습니다.
4-4 변수의 분포 확인 하기
# 연속형 변수 분포 확인
f, ax = plt.subplots(2, 3, figsize = (17, 9))
sns.distplot(bank_1["age"], ax = ax[0,0])
sns.distplot(bank_1["experience"], ax = ax[0,1])
sns.distplot(bank_1["income"], ax = ax[0,2])
sns.distplot(bank_1["family"], ax = ax[1,0])
sns.distplot(bank_1["ccavg"], ax = ax[1,1])
# sns.distplot(bank_1["mortgage"], ax = ax[1,2])
sns.distplot(bank_1["mortgage"][bank_1["mortgage"] != 0], ax = ax[1,2]) # 값이 0 인 데이터 빼고 그리기
plt.show()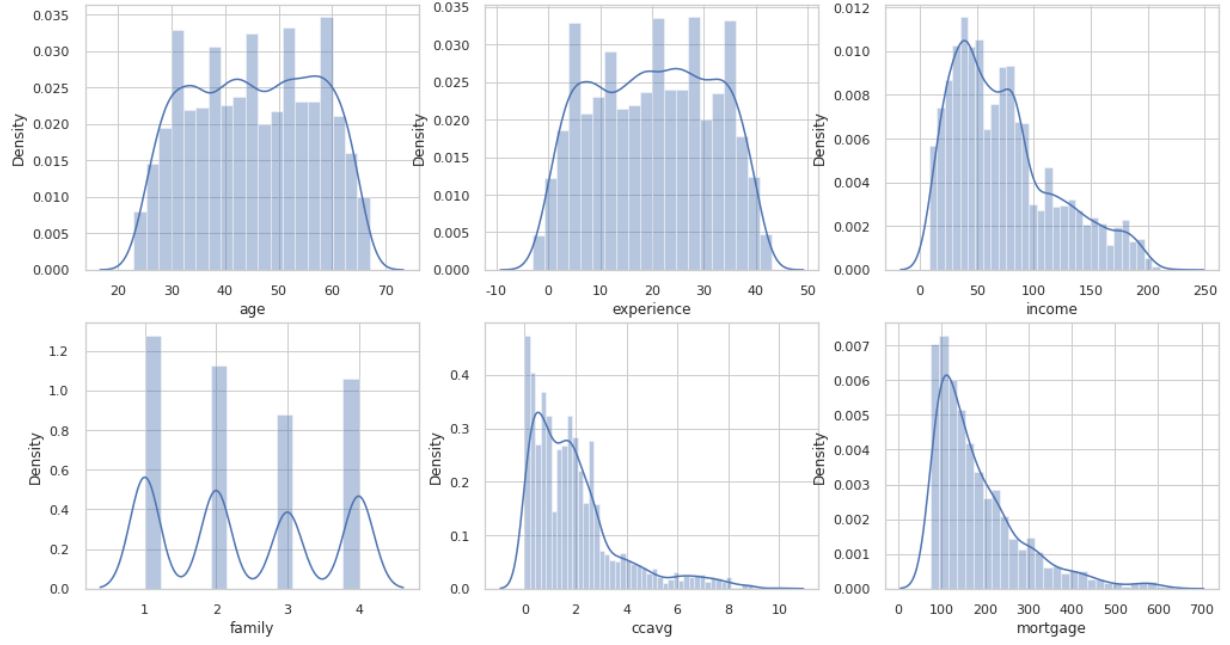
income, ccavg, mortgage 컬럼의 경우, 왼쪽 (낮은쪽)에 많이 분포가 되어 있다는 것을 알 수 있습니다.
# age, experience, income 컬럼의 변수에 대해 자세히 그래프 그리기
# 평균, 25%, 50%, 75% 구간은 선을 그어주기
def drawline(plt, col):
mean = bank_1.describe().loc["mean", col]
m25 = bank_1.describe().loc["25%", col]
m50 = bank_1.describe().loc["50%", col]
m75 = bank_1.describe().loc["75%", col]
plt.axvline(mean, color = "red")
plt.axvline(m25, color = "blue")
plt.axvline(m50, color = "navy")
plt.axvline(m75, color = "purple")
plt.legend({"Mean" : mean, "25%" : m25, "50%" : m50, "75%" : m75})
f, ax = plt.subplots(3, 1, figsize = (12, 13))
pp = sns.distplot(bank_1["age"], ax = ax[0], bins = 10, color = "orange")
drawline(pp, "age")
pp = sns.distplot(bank_1["experience"], ax = ax[1], bins = 10, color = "orange")
drawline(pp, "experience")
pp = sns.distplot(bank_1["income"], ax = ax[2], bins = 10, color = "orange")
drawline(pp, "income")
plt.show()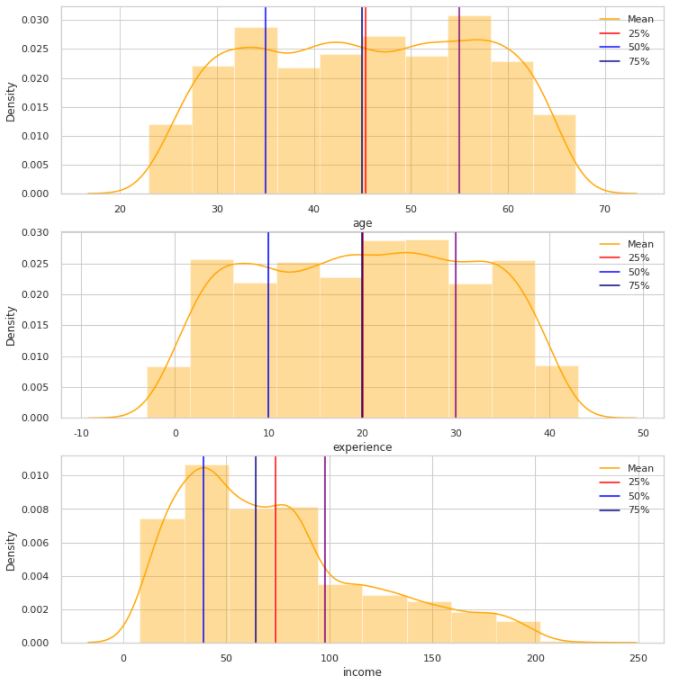
# violin plot 으로 범주형 변수 확인
fig = make_subplots(rows = 1, cols = 3)
fig.add_trace(
go.Violin(
x = bank_1["personal loan"],
y = bank_1["income"]
),
row = 1, col = 1,
)
fig.add_trace(
go.Violin(
x = bank_1["personal loan"],
y = bank_1["age"]
),
row = 1, col = 2,
)
fig.add_trace(
go.Violin(
x = bank_1["personal loan"],
y = bank_1["experience"]
),
row = 1, col = 3,
)
fig.update_traces(
box_visible = True, # 박스 표시
meanline_visible = True, # 중간선 표시
points = False, # 아웃라이어 표시
showlegend = False # 범례 표시
)
fig.update_xaxes(title_text = "personal loan", row = 1, col = 1)
fig.update_xaxes(title_text = "personal loan", row = 1, col = 2)
fig.update_xaxes(title_text = "personal loan", row = 1, col = 3)
fig.update_yaxes(title_text = "income", row = 1, col = 1)
fig.update_yaxes(title_text = "age", row = 1, col = 2)
fig.update_yaxes(title_text = "experience", row = 1, col = 3)
fig.show()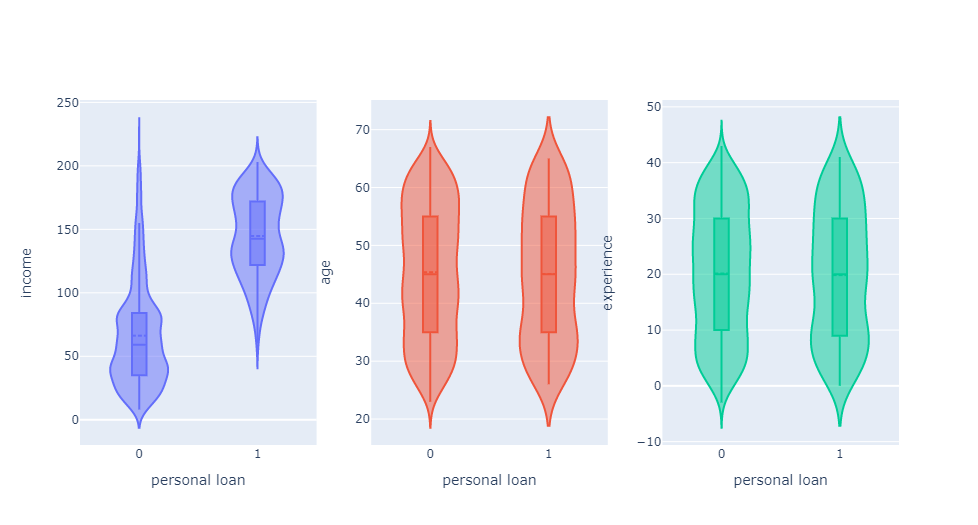
소득이 많은 사람이 소득이 적은 사람보다 대출을 더 많이 많았다는 것을 알 수 있고, 나이와 사회경험은 대출과 연관성이 없다는 것을 알 수 있습니다.
4-5 변수간 상관관계 확인하기
bank_1.corr = bank_1.corr().round(2)
### 히트맵으로 변수간 상관관계 확인
import plotly.figure_factory as ff
fig = ff.create_annotated_heatmap(x = bank_1.corr.index.tolist(),
y = bank_1.corr.columns.tolist(),
z = bank_1.corr.values,
showscale = True)
fig.update_layout(
title = dict(
text = "<b>변수간 상관관계 Heat Map</b>",
y = 0.9,
font_size = 20
),
xaxis = dict(
side = "bottom" # x 축 위치 조정
)
)
fig.show()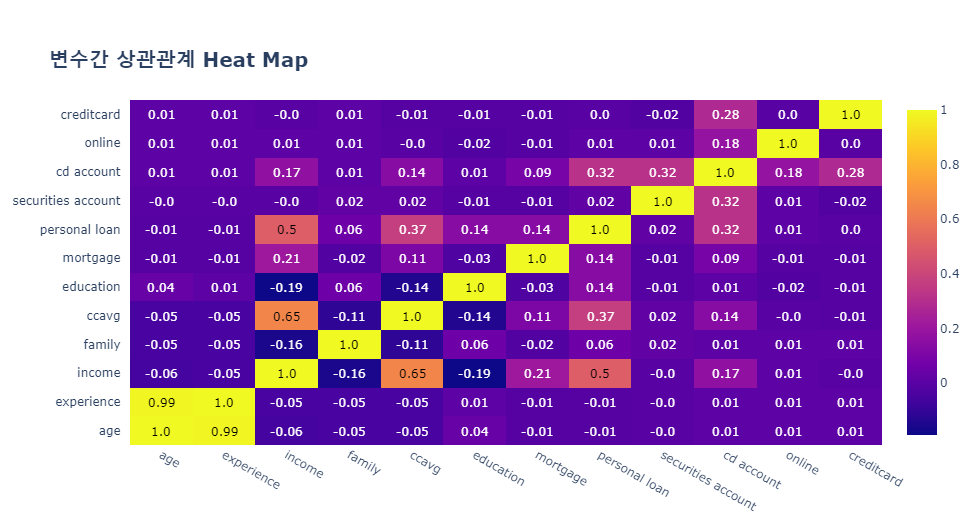
age 와 experience 는 서로 강한 상관관계(0.99)를 가지고 있습니다.
income, ccavg, personal loan 은 중간 정도의 상관관계(0.65, 0.5)를 가지고 있습니다.
personal loan 에 영향을 미치는 변수는 income, ccavg, cd account 있습니다.
4-6 구간화 해서 그래프 그리기
# 신용카드 월 평균 이용금액 구간화
bank_2 = bank_1[["ccavg", "creditcard", "personal loan"]]
bank_2["ccavg_bin"] = pd.cut(bank_2["ccavg"], bins = [0, 2, 4, 6, 100], labels = ["0-2", "3-4", "5-6", "7+"])
bank_2.head()
# 구간별 신용카드 유무와 신용카드 월평균 사용액 집계
df_2 = bank_2.groupby(["ccavg_bin", "creditcard"])["ccavg"].sum().reset_index()
df_2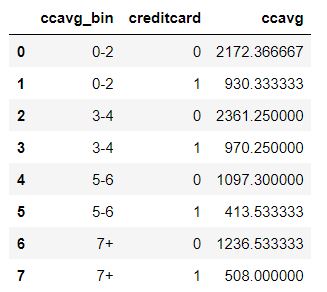
f, ax = plt.subplots(1, 2, figsize = (16, 6))
# 구간별 신용카드 유무와 신용카드 월 평균 사용액 시각화
sns.barplot(data = df_2, x = "ccavg_bin", y = "ccavg", hue = "creditcard", ax = ax[0])
ax[0].set(xlabel = "CC avg bins", ylabel = "Count of customers")
# 수입과 신용카드 월 평균 사용액 시각화
sns.scatterplot(data = bank_1, x = "income", y = "ccavg", hue = "personal loan", ax = ax[1], alpha = 0.6)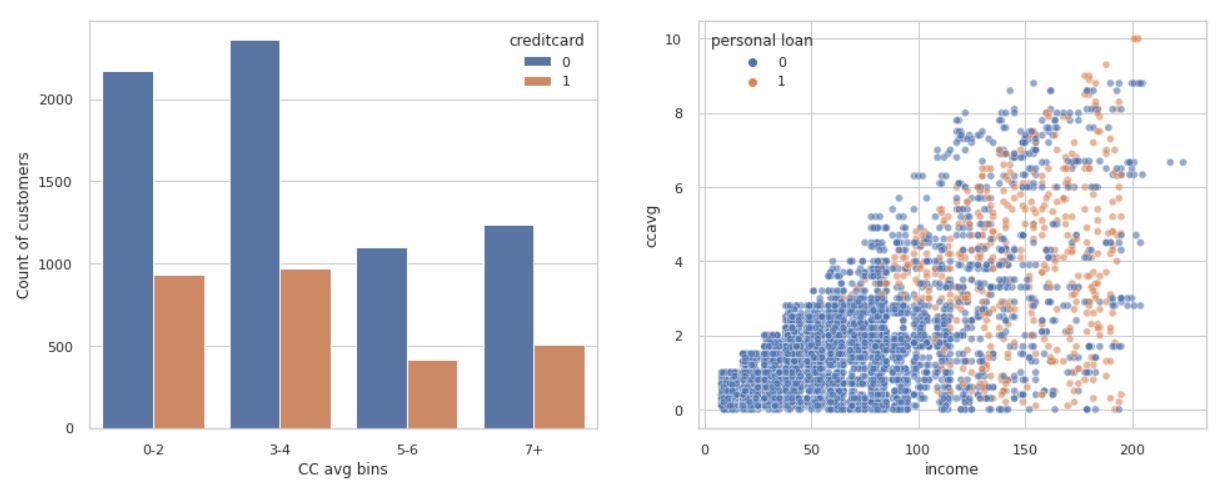
이 은행의 고객은 신용카드를 사용하지 않는 고객이 사용하는 고객보다 훨씬 많으며, 소득이 많고 월 평균 신용카드 사용액이 많을수록 대출을 받는다는 것을 알 수 있습니다.
5. Review
- Personal Loan 데이터는
-> 총 데이터 수 70,000
-> 결측치는 없다.
- 고객의 나이는 23세부터 67세까지 있으며 평균 나이는 45.3세이다.
- 고객의 평균 수입은 73,774.2$이며, 최고수입은 224,000$로 평균의 약 3배이다.
- 수입/월평균신용카드사용량/가족인원수와 대출 사이의 관계는?
-> 대출 받은 사람의 수입이 대출 받지 않은 사람보다 약 2배 정도 높다
-> 대출받은 사람이 받지 않은 사람보다 월 평균 신용카드 사용액이 2배 가량 높다
-> 가족 인원수가 많을 수록 대출 금액이 올라가나 정비례 하지는 않는다
- 월 평균 사용 금액을 구간화 해서 특징을 볼 수 있을까?
-> 이 은행의 고객은 신용카드를 사용하지 않는 고객이 사용하는 고객보다 훨씬 많으며,
소득이 많고 월 평균 신용카드 사용액이 많을수록 대출을 받는다.
'Data Analysis > Kaggle' 카테고리의 다른 글
| [Kaggle] Zomato Bangalore Restaurants 데이터 분석 3 (EDA / 시각화 / 리뷰) (0) | 2021.10.29 |
|---|---|
| [Kaggle] Zomato Bangalore Restaurants 데이터 분석 2 (데이터 전처리) (0) | 2021.10.26 |
| [Kaggle] Zomato Bangalore Restaurants 데이터 분석 1 (데이터 확인 / 질문하기) (0) | 2021.10.26 |
| [Kaggle] Personal Loan 데이터 분석 2 (데이터 전처리) (0) | 2021.10.13 |
| [Kaggle] Personal Loan 데이터 분석 1 (데이터 확인 / 질문하기) (0) | 2021.10.13 |



